2024.04.26美团财务平台 Java一面
2024.04.26美团财务平台 Java一面
1.项目:介绍一下第一个项目
2.介绍一下HashMap;HashMap的哈希冲突较多时会怎么处理
介绍HashMap:
- HashMap 是基于哈希表实现的,使用数组和链表/红黑树组合的形式来存储键值对。
- 具体来说,HashMap 内部维护了一个数组,称为哈希表,每个元素是一个链表的头节点或红黑树的根节点,用于解决哈希冲突。
- 当插入键值对时,通过哈希函数计算键的哈希值,然后将键值对存储到哈希表对应位置的链表或红黑树中。
- 在 JDK 8 中,当链表长度超过一定阈值时,链表会转换成红黑树,以提高查找、插入和删除操作的性能。
HashMap的哈希冲突较多时会怎么处理? 拉链法
- 在Java 8之前,HashMap使用链表来存储哈希冲突的元素,当链表过长时会严重影响性能。
- 为了解决这个问题,Java 8中引入了红黑树来代替过长的链表。当链表长度超过阈值(默认8)时,就会将链表转换为红黑树。这样可以将查找时间复杂度从O(n)提高到O(logn),大幅提高了HashMap的性能。
- 这种动态的切换机制
(链表 -> 红黑树)只存在于HashMap、ConcurrentHashMap和LinkedHashMap中,而Hashtable、WeakHashMap和IdentityHashMap仍然使用链表来解决哈希冲突。
哈希冲突的其他办法:再哈希法。如果某个hash函数产生了冲突,那么再用另外一个hash函数进行计算,一直计算直到不再产生冲突。这种方式会增加计算时间,性能影响较大。比如像布隆过滤器就采用了这种方法。
3.HashMap扩容;多线程情况下HashMap扩容会出现什么问题
HashMap扩容原理
当HashMap中的元素个数超过容量 * 负载因子(默认为0.75)时,HashMap就会触发扩容机制,对哈希表进行扩容。HashMap扩容的具体步骤如下:
- 创建一个容量为原来2倍的新哈希表。
- 重新计算原哈希表中所有元素的哈希值,并将它们插入到新的哈希表中。
- 如果原索引位置上是单个节点,则直接插入到新表对应位置。
- 如果原索引位置上是链表或红黑树,需要将链表或红黑树拆分,根据新的哈希值重新组织到新表上。
- 将原哈希表的引用指向新的扩容后的哈希表。
- 把原哈希表中的所有元素都转移到新哈希表中。
多线程情况下HashMap扩容会出现什么问题?
JDK1.7中的 HashMap 使用头插法插入元素,在多线程的环境下,扩容的时候有可能导致环形链表的出现,形成死循环。因此,JDK1.8使用尾插法插入元素,在扩容时会保持链表元素原本的顺序,不会出现环形链表的问题。
4.有没有线程安全的Map
ConcurrentHashMap 在 JDK 1.7 时,使用的是分段锁也就是 Segment 来实现线程安全的。 然而它在 JDK 1.8 之后,使用的是 CAS + synchronized 或 CAS + volatile 来实现线程安全的。
5.String a = "abc"和String a = new String("abc")区别
- java运行环境有一个字符串池,由String类维护。执行语句String str="abc"时:首先查看字符串池中是否存在字符串"abc",如果存在则直接将“abc”赋给str,如果不存在则先在 字符串池中新建一个字符串"abc",然后再将其赋给str.
- 执行语句String str = new String("abc");时。不管字符串池中是否存在字符串“abc”,直接新建一个字符串“abc”(注意新建的字符串“abc”不是在字符串池中,而是在堆中),然后将其赋给str。这种效率低于使用字符串池的方式。
6.String a = "abc"对它进行修改,改为"def" 发生什么
对于字符串 String a = "abc"进行修改的情况:
在初次声明
a = "abc"时,这个字符串"abc"会被创建并存储在Java堆中。此时,变量a会指向这个字符串对象在堆中的地址。当您尝试修改
a为"def"时,即a = "def",实际上是将变量a重新指向了另一个字符串对象"def",而不是修改原有的"abc"对象。原来的字符串"abc"对象依然存在于堆中,只是不再有任何引用指向它了,变成了"垃圾"(Garbage)对象,等待被Java的垃圾收集器回收。
这是因为Java中的字符串是不可变的(immutable),一旦创建就不能被修改。每次对字符串进行操作,都会创建一个新的字符串对象。
所以,对于 String a = "abc" 进行修改操作, a = "def"只是改变了变量a指向的字符串对象,而不会修改原有的字符串"abc"。原有的"abc"字符串对象仍然存在于堆中,直到被垃圾收集器回收。
7.int和Integer区别,int a=200和Integer=200一样吗
Integer是int的包装类,int则是java的一种基本数据类型 ;
Integer变量必须实例化后才能使用,而int变量不需要 ;
Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值;
Integer的默认值是null,int的默认值是0;
interger缓存池范围-128 ~ 127 ,所以这两个不一样
8.TCP三次握手
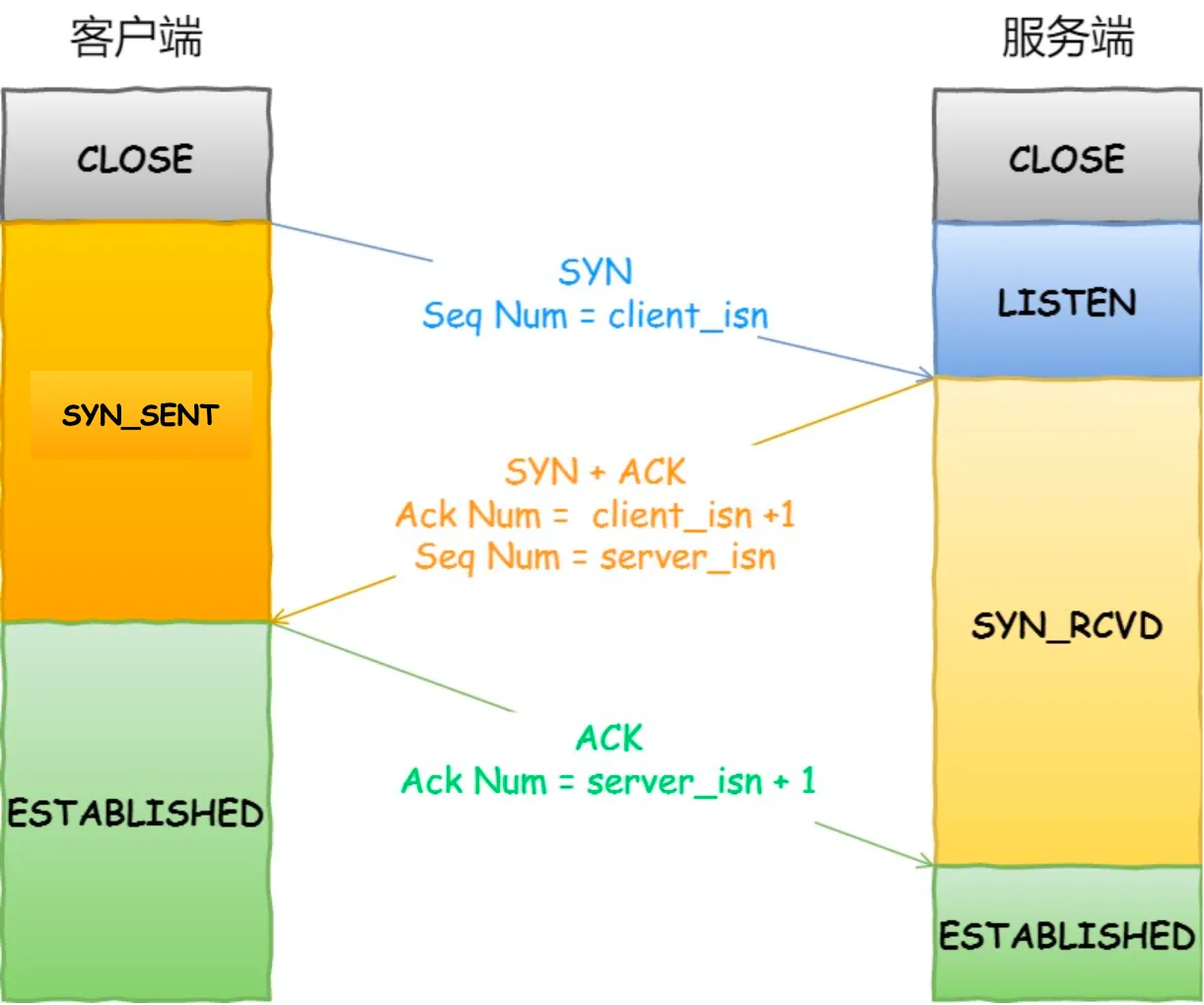
- 一开始,客户端和服务端都处于 CLOSE 状态。先是服务端主动监听某个端口,处于 LISTEN 状态
- 客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN(同步序列编号) 标志位置为 1,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。
- 服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK(确认编号) 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态。
- 客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务端的数据,之后客户端处于 ESTABLISHED 状态。服务端收到客户端的应答报文后,也进入 ESTABLISHED 状态。
9.线程池参数;若核心线程数为20,最大线程数为30,阻塞队列长度为100,线程池可以处理多少任务
todo
10.介绍一下Threadlocal,需要注意什么
todo
11.索引是怎么实现的;b+树有什么好处
todo
12.聚簇索引和非聚簇索引
todo
13.若联合索引a,b,c,则SQL"select b,c from ..." 有没有用到索引
todo
14.MySQL事务的隔离级别
MySQL事务的隔离级别主要为:读未提交、读已提交、可重复读、串行化
15.Redis为什么这么快;什么是缓存穿透
Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
- Redis 基于内存,内存的访问速度比磁盘快很多;
- Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
- Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
- Redis 通信协议实现简单且解析高效。
缓存穿透:查询一个不存在的数据,由于缓存中不存在,请求会直接到达数据库,如果大量这样的请求发生,对数据库造成压力,导致服务不可用。
16.介绍一下SpringIoC
IOC(Inversion of Control,控制反转)是一种设计模式,它颠覆了传统的代码编写方式,将对象的创建和依赖管理的控制权从程序本身转移到外部容器(如框架或库)。是一种思想不是一个技术实现。
IOC 的核心思想是:
- 创建对象的控制权不在程序内部,而是交由外部容器负责。
- 对象之间的依赖关系也由外部容器来管理,程序不需要自己管理依赖。
例如:现有类 A 依赖于类 B
- 传统的开发方式 :往往是在类 A 中手动通过 new 关键字来 new 一个 B 的对象出来
- 使用 IoC 思想的开发方式 :不通过 new 关键字来创建对象,而是通过 IoC 容器(Spring 框架) 来帮助我们实例化对象。我们需要哪个对象,直接从 IoC 容器里面去取即可。
为什么叫控制反转?
- 控制 :指的是对象创建(实例化、管理)的权力
- 反转 :控制权交给外部环境(IoC 容器)
17.说一下JVM垃圾回收机制;垃圾回收的常用方法
垃圾回收的过程?
- 垃圾分类(Garbage Classification):垃圾回收器首先需要确定哪些对象是垃圾对象,哪些对象是存活对象。一般情况下,垃圾回收器会从堆的根节点(如程序计数器、虚拟机栈、本地方法栈和方法区中的类静态属性等)开始遍历对象图,标记所有可以到达的对象为存活对象,未被标记的对象则被认为是垃圾对象。
- 垃圾查找(Garbage Tracing):垃圾回收器需要查找出所有垃圾对象,以便进行清理。垃圾查找的方式不同,会导致不同的垃圾回收算法。常见的垃圾查找算法有标记-清除算法、复制算法、标记-整理算法、分代算法等。
- 垃圾清理(Garbage Collection):垃圾回收器需要将所有的垃圾对象进行清理。垃圾清理的方式也不同,常见的有标记-清除算法、复制算法、标记-整理算法、分代算法等。垃圾清理可能会引起应用程序的暂停,不同的垃圾回收器通过不同的方式来减少这种暂停时间,从而提高应用程序的性能和可靠性。
说一下Java的GC算法?
- 可达性分析算法:通过一些GC Roots作为起点,当一些对象没有任何引用链能够到达时,则证明该节点是不可用,是需要回收的,也就是通过GC Roots无法到达的对象就是可回收对象。
- 标记-清除算法:分为两步走,首先把内存中的对象进行标记,然后把可回收的单独拿走,这样的缺点是会产生大量的内存碎片,下次如果有有大对象创建的时候就会发现内存不够,又触发一次垃圾回收,但是实际上内存是够的,只是不能连续使用,因为我们申请内存空间的时候是需要连续的一片。
- 复制算法:将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后清除掉使用过的这一半。但是代价就是内存利用率太低。
- 标记-整理算法:标记过程仍然与标记 — 清除算法一样,然后让所有存活的对象都向一端移动,再清理掉端边界以外的内存区域。标记整理算法在标记-清除算法上做了升级,解决了内存碎片的问题,也规避了复制算法只能利用一半内存区域的弊端,但它对内存变动更频繁,需要整理所有存活对象的引用地址,在效率上比复制算法要差很多。
- 分代收集算法:分代收集算法,是融合上述3种基础的算法思想,而产生的针对不同情况所采用不同算法的一套组合。根据对象存活周期的不同将内存划分为几块。一般是把 Java 堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象是待回收的,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高,就使用标记-清除或标记-整理算法来进行回收。
18.手撕:求根节点到叶节点数字之和
DFS解法
class Solution {
public:
int res=0;
void dfs(TreeNode* root,int fa) {
fa=fa*10+root->val;
if(root->left) dfs(root->left,fa);
if(root->right) dfs(root->right,fa);
if(root->left==nullptr &&root->right==nullptr) res+=fa;
}
int sumNumbers(TreeNode* root) {
dfs(root,0);
return res;
}
};
DFS另一种写法:
class Solution {
public:
int dfs(TreeNode* root,int fa){
if(root==nullptr) return 0;
fa=fa*10+root->val;
if(root->left==nullptr &&root->right==nullptr) return fa;
return dfs(root->left,fa)+dfs(root->right,fa);
}
int sumNumbers(TreeNode* root) {
return dfs(root,0);
}
};
BFS写法:
class Solution {
public:
int sumNumbers(TreeNode* root) {
int res=0;
queue<pair<TreeNode*,int>> q;
q.push({root,root->val});
while(!q.empty()){
auto [node,val]=q.front();
q.pop();
if(node->left==nullptr &&node->right ==nullptr) res+=val;
else {
if(node->left) q.push({node->left,val*10+node->left->val});
if(node->right) q.push({node->right,val*10+node->right->val});
}
}
return res;
}
};