ikun伙伴匹配系统优化
大约 5 分钟约 1519 字
ikun伙伴匹配系统优化
以下优化均是在用户量为100万的情况下进行:
分布式Session登录
⽤户登录:使⽤ Redis 实现分布式 Session,解决集群间登录态同步问题;并使⽤ Hash 代替
String 来存储⽤户信息,节约了 xx% 的内存并便于单字段的修改。
节省内存的原因是不⽤保存序列化对象信息或者 JSON 的⼀些额外字符串
使⽤ Easy Excel 读取收集来的基础⽤户信息,并通过⾃定义线程池 + CompletableFuture 并
发编程提⾼批量导⼊数据库的性能。实测导⼊ 100 万⾏的时间从 xx 秒缩短⾄ xx 秒。(需要
⾃⼰实际测试对⽐数据)
Redis缓存首页高频访问用户
使⽤ Redis 缓存⾸⻚⾼频访问的⽤户信息列表,将接⼝响应时⻓从 216ms缩短⾄ 43ms。且通
过⾃定义 Redis 序列化器来解决数据乱码、空间浪费的问题。
不使用redis进行缓存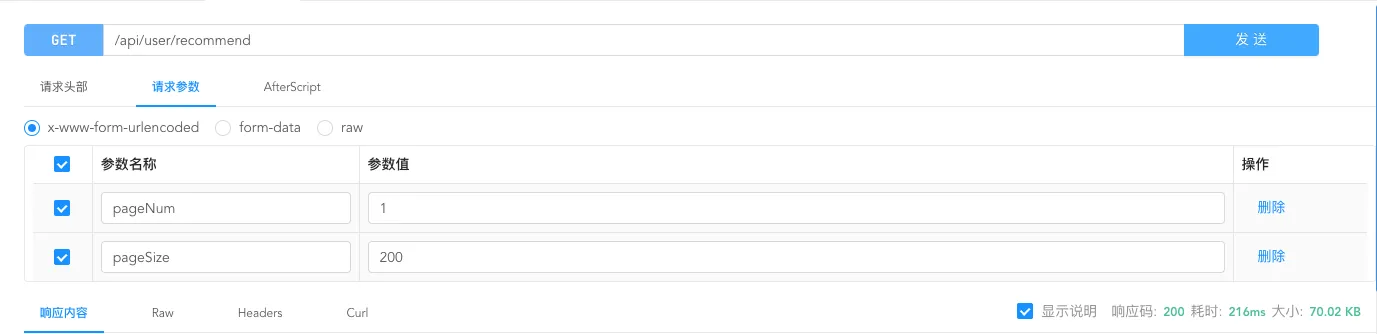
使用redis进行缓存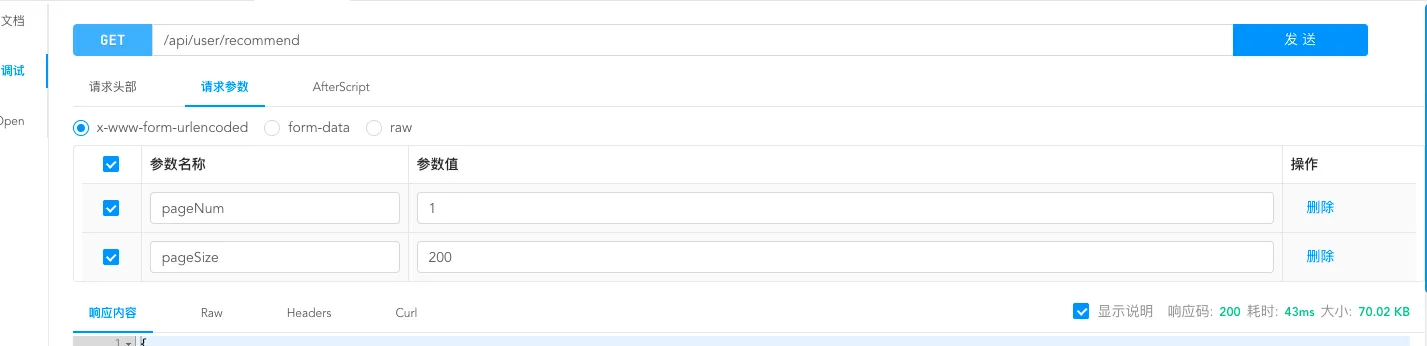
定时任务缓存预热
为解决⾸次访问系统的⽤户主⻚加载过慢的问题,使⽤ Spring Scheduler 定时任务来实现缓存
预热,并通过分布式锁保证多机部署时定时任务不会重复执⾏。
缓存的时候只给重要客户 进行缓存,例如vip
@Resource
private RedisTemplate<String, ObjectKey> redisTemplate;
private List<Long> mainUserList = Arrays.asList(1L);
@Resource
private RedissonClient redissonClient;
//每天的23点59执行
@Scheduled(cron = "0 59 23 * * *")
public void doCacheRecommendUser() {
String redisKey1 = "ikun:precacheJob:docache:lock";
RLock lock = redissonClient.getLock(redisKey1);
try {
if (lock.tryLock(0, 30000, TimeUnit.MICROSECONDS)) {
for (Long userId : mainUserList) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
Page<User> page = userService.page(new Page<>(1, 10), queryWrapper);
String redisKey = String.format("ikun:user:recommend:%s", userId);
ValueOperations valueOperations = redisTemplate.opsForValue();
try {
valueOperations.set(redisKey, page.getRecords());
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//只能释放自己的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
加入队伍锁
为解决同⼀⽤户重复加⼊队伍、⼊队⼈数超限的问题,使⽤ Redisson 分布式锁来实现操作互
斥,保证了接⼝幂等性。
@Override
public boolean joinTeam(TeamJoinDTO teamJoinDTO, User loginUser) {
if (teamJoinDTO == null) {
throw new BussinessException(Code.PARAMS_ERROR);
}
Long teamId = teamJoinDTO.getTeamId();
Team team = getTeamById(teamId);
if (team.getExpireTime() != null && team.getExpireTime().before(new Date())) {
throw new BussinessException(Code.PARAMS_ERROR, "队伍已过期");
}
if (team.getStatus().equals(TeamStatusEnum.PRIVATE)) {
throw new BussinessException(Code.NULL_ERROR, "禁止加入私有队伍");
}
String password = teamJoinDTO.getPassword();
if (team.getStatus().equals(TeamStatusEnum.PASSWORD)) {
if (StringUtils.isBlank(password) || !password.equals(team.getPassword())) {
throw new BussinessException(Code.PARAMS_ERROR, "密码错误");
}
}
Long userId = loginUser.getId();
//分布式锁
RLock lock = redissonClient.getLock("ikun:join_team");
try {
while (true) {
if (lock.tryLock(0, 30000, TimeUnit.MICROSECONDS)) {
System.out.println("getLock" + Thread.currentThread().getId());
QueryWrapper<UserTeam> userTeamQueryWrapper = new QueryWrapper<>();
userTeamQueryWrapper.eq("userId", userId);
long count = userTeamService.count(userTeamQueryWrapper);
if (count > 5) {
throw new BussinessException(Code.PARAMS_ERROR, "最多创建和加入五个队伍");
}
//不能重复加入已加入的队伍
userTeamQueryWrapper = new QueryWrapper<>();
userTeamQueryWrapper.eq("userId", userId);
userTeamQueryWrapper.eq("teamId", teamId);
long count2 = userTeamService.count(userTeamQueryWrapper);
if (count2 > 0) {
throw new BussinessException(Code.PARAMS_ERROR, "不能重复加入已加入的队伍");
}
//已加入队伍的人数
long count1 = countTeamUserByTeamId(teamId);
if (count1 >= team.getMaxNum()) {
throw new BussinessException(Code.PARAMS_ERROR, "队伍已满");
}
//插入用户=>队伍关系到关系表
UserTeam userTeam = new UserTeam();
userTeam.setUserId(userId);
userTeam.setTeamId(teamId);
userTeam.setJoinTime(new Date());
return userTeamService.save(userTeam);
}
}
} catch (Exception e) {
throw new BussinessException(Code.SYSTEM_ERROR);
} finally {
//只能释放自己的锁
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
编辑距离算法优化
使⽤编辑距离算法实现了根据标签匹配最相似⽤户的功能,并通过优先队列来优化 TOP N 运
算过程中的内存占⽤。
原来是先一次性把数据全部都查出来,然后再排序,取出前N名:
private List<User> matchUsersByListSorted(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
List<User> userList = this.list(queryWrapper);
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
List<Pair<User, Long>> list = new ArrayList<>();
for (int i = 0; i < userList.size(); i++) {
User user = userList.get(i);
String userTags = user.getTags();
//无标签或者是自己,跳过
if (StringUtils.isBlank(userTags) || user.getId().equals(loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
int distance = AlgorithmUtils.minDistance(tagList, userTagList);
list.add(new Pair<>(user, (long) distance));
}
//按照编辑距离从小到达排序 编辑距离越小说明相似度越高
List<Pair<User, Long>> topUserPairList = list.stream()
.sorted((a, b) -> (int) (a.getValue() - b.getValue()))
.limit(num)
.collect(Collectors.toList());
List<Long> userIdList = topUserPairList.stream().map(userLongPair -> userLongPair.getKey().getId()).collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", userIdList);
Map<Long, List<User>> userIdUserListMap = this.list(userQueryWrapper)
.stream()
.map(this::getSafetyUser)
.collect(Collectors.groupingBy(User::getId));
List<User> finalUserList = new ArrayList<>();
for (Long userId : userIdList) {
finalUserList.add(userIdUserListMap.get(userId).get(0));
}
return finalUserList;
}
使用优先队列优化空间,只需要维护num个数据即可:
public List<User> matchUsersByPriorityQueue(long num, User loginUser) {
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.select("id", "tags");
queryWrapper.isNotNull("tags");
// 获取所有用户列表
List<User> userList = this.list(queryWrapper);
// 获取登录用户的标签
String tags = loginUser.getTags();
Gson gson = new Gson();
List<String> tagList = gson.fromJson(tags, new TypeToken<List<String>>() {
}.getType());
// 创建一个优先队列,按照距离进行排序 队列始终保持最小距离的用户,每次删除编辑距离值最大的那个
PriorityQueue<Pair<User, Long>> priorityQueue = new PriorityQueue<>((a, b) -> (int) (b.getValue() - a.getValue()));
// 遍历所有用户,计算距离并加入优先队列
for (User user : userList) {
String userTags = user.getTags();
if (StringUtils.isBlank(userTags) || user.getId().equals(loginUser.getId())) {
continue;
}
List<String> userTagList = gson.fromJson(userTags, new TypeToken<List<String>>() {
}.getType());
int distance = AlgorithmUtils.minDistance(tagList, userTagList);
priorityQueue.offer(new Pair<>(user, (long) distance));
// 保持优先队列的大小不超过 num
if (priorityQueue.size() > num) {
priorityQueue.poll();
}
}
//获取id列表
List<Long> matchUserIds = priorityQueue.stream()
.map(userLongPair -> userLongPair.getKey().getId())
.collect(Collectors.toList());
QueryWrapper<User> userQueryWrapper = new QueryWrapper<>();
userQueryWrapper.in("id", matchUserIds);
List<User> users = this.list(userQueryWrapper)
.stream()
.map(this::getSafetyUser)
.collect(Collectors.toList());
return users;
}
将两种方法进行测试比较
@Override
public List<User> matchUsers(long num, User loginUser) {
//先查一次数据库,防止数据库连接耗时。影响了下面的对比
this.getById(loginUser.getId());
long startTime1 = System.currentTimeMillis();
List<User> users1 = matchUsersByListSorted(num, loginUser);
long endTime1 = System.currentTimeMillis();
long executionTime1 = endTime1 - startTime1;
long startTime2 = System.currentTimeMillis();
List<User> users2 = matchUsersByPriorityQueue(num, loginUser);
long endTime2 = System.currentTimeMillis();
long executionTime2 = endTime2 - startTime2;
log.info("使用list排序耗时:{}ms,使用优先队列耗时:{}ms,差距:{}ms,优化比例:{}%",
executionTime1, executionTime2, executionTime1 - executionTime2,
(executionTime1 - executionTime2) * 100 / executionTime1);
return users2;
}
结果如下: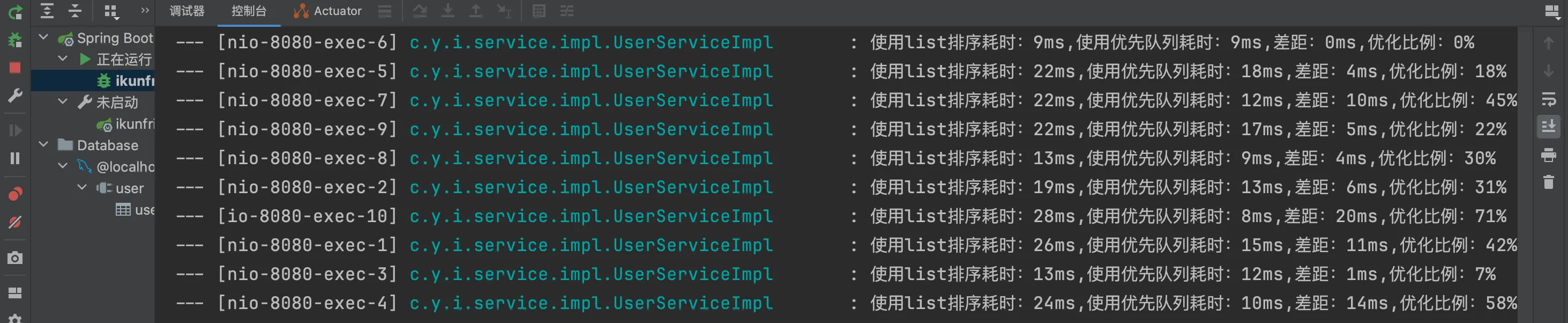
通过测试类进行测试:
@Test
void matchUsers() {
int num = 10;
User user = userService.getById(1001);
long costTime1 = 0;
long startTime1 = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
List<User> users1 = userService.matchUsersByListSorted(num, user);
}
long endTime1 = System.currentTimeMillis();
costTime1 = endTime1 - startTime1;
long startTime2 = System.currentTimeMillis();
for (int i = 0; i < 100; i++) {
List<User> users2 = userService.matchUsersByPriorityQueue(num, user);
}
long endTime2 = System.currentTimeMillis();
long costTime2 = endTime2 - startTime2;
log.info("100运算情况下:List排序耗时:{}ms,优先队列耗时:{}ms,相差:{}ms,优化比例:{}%", costTime1, costTime2, costTime1 - costTime2,
(costTime1 - costTime2) * 100 / costTime1);
}
结果如下: